一. 通过爬取煎蛋网随手拍,下载网页上的图片。
1.煎蛋网不知道是什么原因把以前妹子图的地址改成随手拍,而且他下面的页码在超过一定页数(目测35页左右),就会删除掉前面几页的内容。他页面地址http://jandan.net/ooxx/page-32#comments, 32就是他的页码数。我们首先需要知道他首页的页码,然后后面-=1,直到1。
Chrome浏览器在随手拍页面首页审查元素,看到current-comment-page就是首页第32页的代码位置,所以知道我们找到这个标签就可以确定首页的页码。我使用了BeautifulSoup,得到每个页面的文本soup数据函数data(url)就可以查找到该标签。函数getpage(soup)代码第40行soup.find_all('span', attrs={'class':'current-comment-page'}), 随后再通过函数getpage(soup)其他页面的地址就很容易了。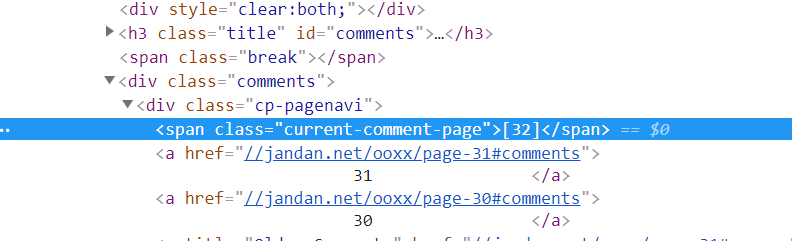
2.得到页面地址后,我们就需要知道每个页面上所有图片的地址。
任意一张页面上的图片鼠标右键审查元素可以看到标签的组成,可以看到原图地址就是把mw600改为large。所以我们只要找到这个标签就可以了。函数downpic(soup)第57行soup.find_all('a', attrs={'class':'view_img_link'})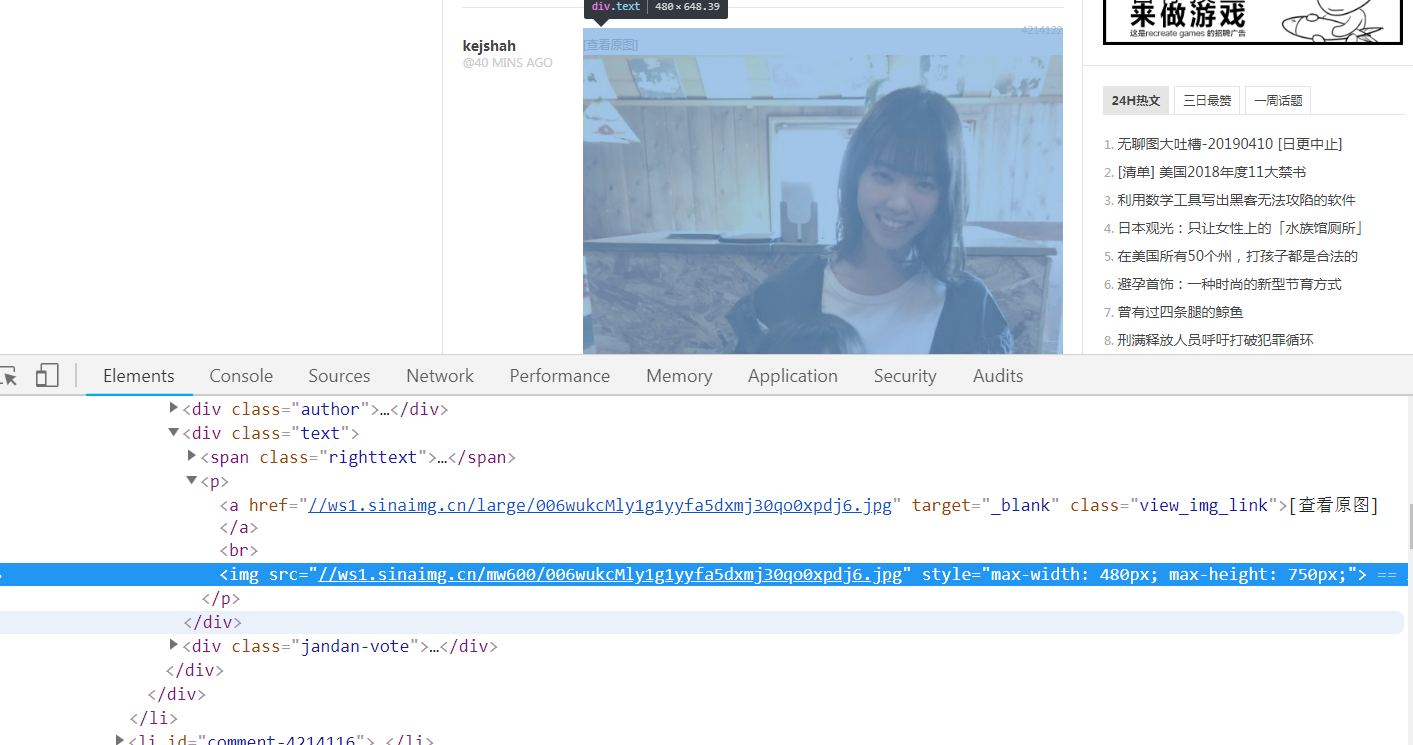
其实在我刚写这段代码时,煎蛋网的还采用了反爬机制,对地址进行了加密,所以我代码中还保留的那部分内容作为备注。参考前辈的例子Python爬虫爬取煎蛋网无聊图,煎蛋网也是用心良苦啊,栏目名字都改来来去的。
3.然后就可以读取图片地址的数据,下载图片。下载图片实际上就是把图片的数据写入一个新的图片文件里。函数downpic(soup)第78,79行。
4.完善代码。以及其中遇到的问题。
检测网页的编码。自然用到chardet.但是有时会出现不名的原因导致检测的编码类型有误,导致页面有乱码,查找不到我们想要的标签。本来是utf-8, 得到的结果是windows-1254,这是什么鬼,我也不知道,查了很久终于在一篇文章中找到了解决方法,见下面应用内容。参考再也不用担心网页编码的坑了, 把response.encoding = None, 运行一下再改过来 = code.问题就解决了。这里还要注意,chardet.detect的参数是二进制数据,response.text是文本数据,.content才是二进制数据。
1
2
3code = chardet.detect(response.content)['encoding']
response.encoding = code
html = response.text那么当你发现response.text返回乱码的时候,怎么办呢。。。
只要先设置编码为None…
再打印.text就可以了..
1
2
3> response.encoding = None
> response.text
>为了不重复下载以前下载过的图片(毕竟每天图片都在更新), 所以我使用pickle把所有的图片名保存在了文件里,再下载时,先读取保存的文件(一个列表以二进制的数据保存),列表中没有的图片名才下载。由于网站保存的图片名都是固定的,所以当遇到旧的图片名时就可以停止下载。如果把每次出现的新图片都储存在文件里,势必让文件越来越大,为了解决这个问题,我把新图片名写入一个临时文件,再写入一个旧的图片名,最后删除原来的文件,把临时文件改名为正式文件。这样每次下载完后只保存了新的图片名和一个旧图片名作为下载的终点。
同时为了让函数downpic(soup)读取到旧图片名时让函数和主程序main()都立刻停止循环执行下面的脚本不要再重复读取页面数据,就需要从函数中发出一个信号,让程序终止。我使用了raise语句来引发一个异常,我自定义了一个Stopdownload()的异常, 函数和主程序都可以通过接受到异常来终止程序。
代码如下:
1 | import requests |
二.对已下载图片进行分类
虽然自动下载了图片,但是是否是自己喜欢的,还要自己去判断(没有非人工智能高大上),这段代码就是实现了自动显示图片,自己再选择是否喜欢,并把图片保存在不同的文件夹里。使用了matplotlib.pyplot, PIL/Image, shutil, easygui这四个库。
在写这段代码时遇到os.chdir('C:\Users\vulcanten\Desktop\test')出现异常,原因是\在字符串中是当作转义字符来使用, 所以出现了报错,我们只要在使用路径名时在前面加上r, 就可以解决了 os.chdir(r'C:\Users\vulcanten\Desktop\test'), 还可以使用\\, 或者/来代替。
1 | #对下载的图片进行分类 |
上图看一下效果
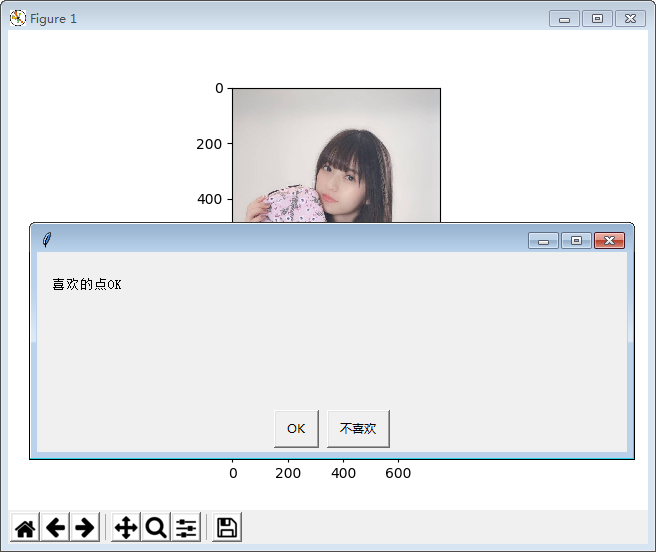
运行后发现这个代码运行速度比较慢,还没有使用图片查看器再结合键盘的删除键来的快。虽然如此,但代码还是提供了一些有用的思路,以备今后使用。
本文离不开以下文章的贡献:
python中使用PIL和matplotlib.pyplot打开显示关闭暂停和保存图片
总结:
在函数中使用raise来引起异常,实现终止程序的功能。
自定义异常的方法
用shutil在移动或者复制文件
实现滚动显示图片的功能
写爬虫最难的是遇到反爬机制,但是自己又看不懂Jason文件。