上一篇我们安装编码检测工具chardet, 小甲鱼老师有道题要求用户输入任意网址,我们通过脚本判断出该网站使用的编码方式。
题目演示:
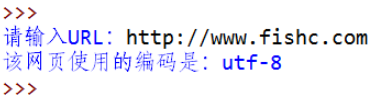
下面是我的代码:
1 | '''本脚本是利用文本编码检测工具chardet检测用户输入的网站所使用的编码。''' |
总结:
要注意
1 | __name__ == '__main__': |
的使用
上一篇我们安装编码检测工具chardet, 小甲鱼老师有道题要求用户输入任意网址,我们通过脚本判断出该网站使用的编码方式。
题目演示:
1 | '''本脚本是利用文本编码检测工具chardet检测用户输入的网站所使用的编码。''' |
总结:
要注意
1 | __name__ == '__main__': |
的使用