第一步:使用百度云文字识别出单张单词图片
看完权力游戏后我买了一套原著,用了差不多6个月读完第一本。第二本还在继续拜读中。。

从79页开始遇到不认识的单词都有用有道词典查询并保存了单词卡片如图,这是我保存的第一张英语卡片.

我就想以后可以把这些单词卡可以整理出来复习一下这些单词。
第一个问题:我想知道在这本书中我查询的单词次数最多的是哪些,这些单词就是我最需要记住的了。
要解决这个问题,我想需要分以下几步:
- 用python识别出单个单词卡的单词
- 利用遍历,循环识别出所有单词,并记录重复单词的次数
- 列出top榜单
第1步:用python识别出单个单词卡的单词
查了一些资料最终使用百度人工智能(免费)中的文字识别现有的API接口
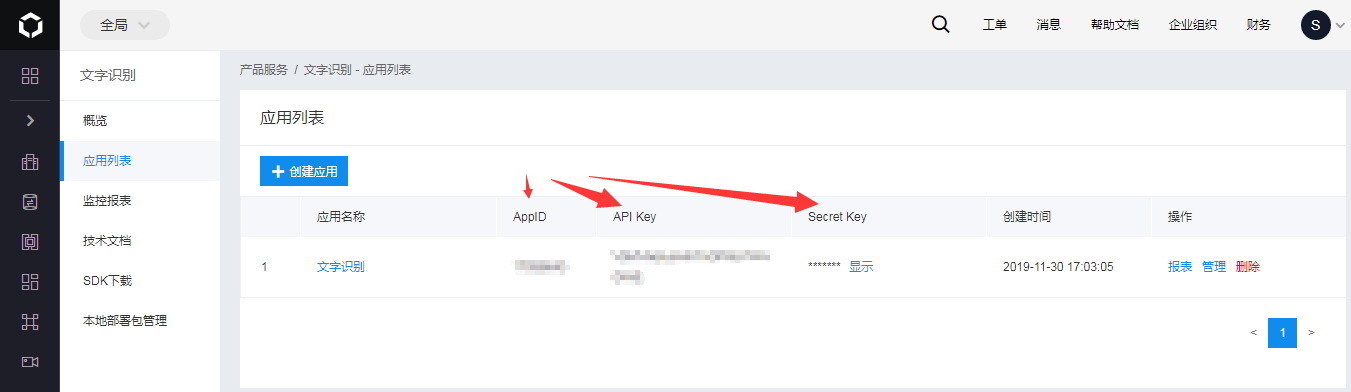
1.注册百度云进入文字识别,有百度账号的直接登录:https://cloud.baidu.com/product/ocr, 然后点创建应用后就可以得到如图的三个参数
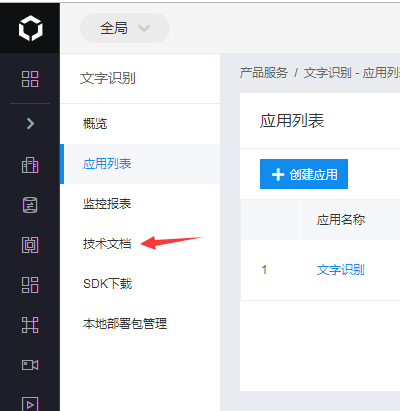
2.然后查看技术文档的python部分
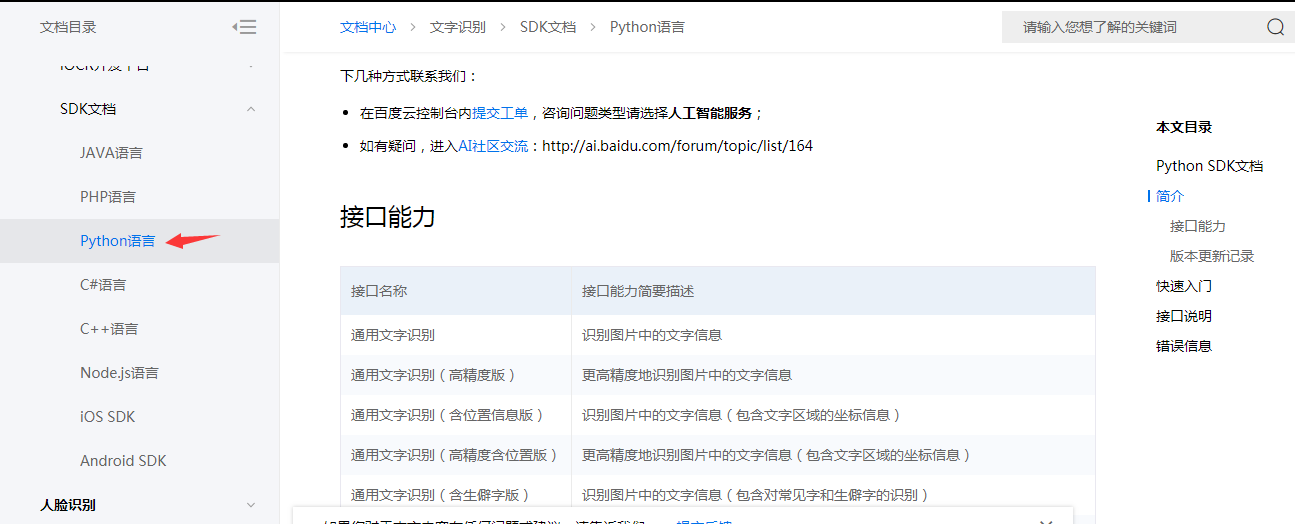
里面的内容浅显易懂,现在用的的接口是通用文字识别,实测高精度版在识别这些单词上没有通用文字识别准确,下面举例说明。
然后用pip安装baidu api ,代码:pip install baidu-aip 如果遇到出错可以多试几次就可以了。
通用文字识别的代码:
1 | from aip import AipOcr |
这样得到的是一个包含图片信息的字典,以第一张图片为例:
1 | image = get_file_content('2019-05-08 234422.png') |
结果为:
1 | {'log_id': 2967069863786893502, 'words_result_num': 4, 'words_result': [{'words': 'labyrinth'}, {'words': "/'laeberIne/"}, {'words': 'n.迷宫;[解剖]迷路;难解的事物'}, {'words': '道网易有道词典'}]} |
如果用高精版:
1 | image = get_file_content('2019-05-08 234422.png') |
结果为:
1 | {'log_id': 7443256712844240862, 'words_result_num': 4, 'words_result': [{'words': ' abyrinth'}, {'words': " /'laeberin0/"}, {'words': 'n.迷宫;[解剖]迷路;难解的事物'}, {'words': '有道网易有道词典'}]} |
可以看出单词labyrinth通用基础版辨别的单词为:{'words': 'labyrinth'}, 而高精度版为:{'words': ' abyrinth'},很明显后者少了一个‘l’, 但是音标都不怎么准确,这个问题后面再查资料看能不能解决。就目前我们需要的信息看,暂时用通用版比较准确。
到这里第1步就很简单解决了,要得到最终的单词只要读取这个字典就可以了
1 | wordsineed = wordsinfo['words_result'] |
结果:
1 | labyrinth |
未完待续。。