第二步:测试部分英语卡片识别,生成一个排序列表
在第一步,我们用百度云普通识别出了单张图片的单词,今天我们需要测试识别少量的图片,并用pickle把单词和查询次数组成的字典归档,另外还要把卡片路径和它对应的单词组成的字典归档。第二个字典文件的键是卡片路径,值是单词,这样是因为路径是唯一的,同一个单词会有若干次查询,可能会有好几张图片,我们为了记录每张图片对应的路径才这样设置。
代码如下:
1 | from aip import AipOcr |
测试文件共81个
测试得到的列表:
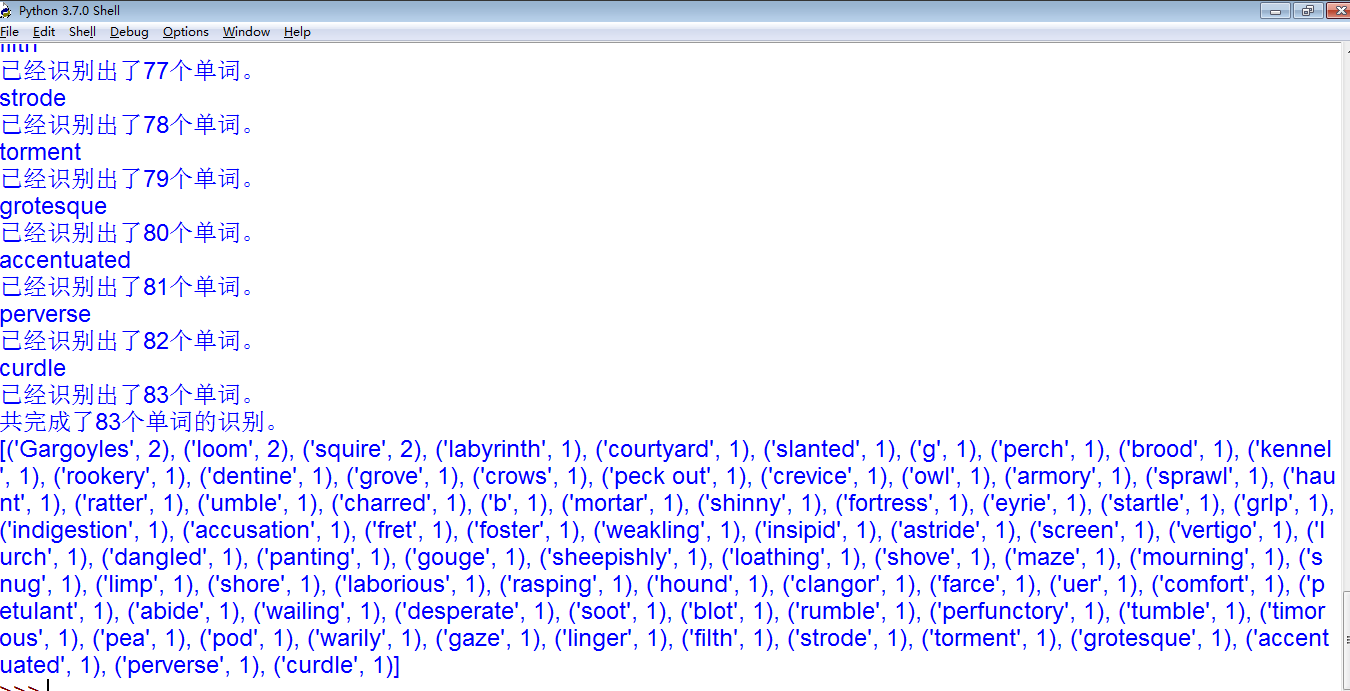
我们可以看到识别出了共81张图片,以及所有单词和查询次数的汇总,还有生成的两个二进制文件,sumwords储存着单词和对应的次数,wordsroot是存着绝对路径和对应的单词。但是我们可以看到,里面有些单词只有一个单字母或者很奇怪的单词如:(‘g’, 1), (‘b’, 1), (‘grIp’, 1). 很明显这是因为普通识别不能很精确的识别一些图片导致的,虽然我们在第一步里面也看到精确识别的问题,但是总体上来说精确还是更优势一些。但我们的问题又来了,百度云里面对于免费用户来说,精确识别的服务只有每天500次,对于还算有点庞大的数据来说根本不够啊。
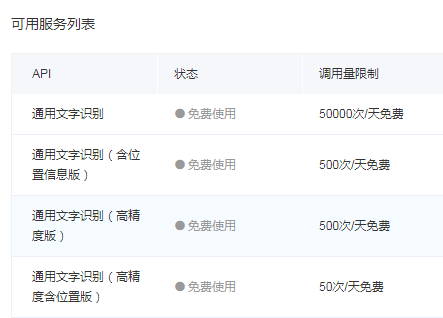
开通的价格对于我们这种底层玩家来说太贵了,我想两本书下来就有差不多一万张图片了。
所以呢我们只有先用普通识别出绝大多数的单词后,再挑出其中未被准确识别的单词和他对应路径,再通过精确识别识别出来就可以了,每天500次就够了。第三步我们就做这个工作。
未完待续。。。。