第三步:测试部分英语卡片识别,建立需要精确识别的单词列表文件
我们在第二步中使用百度云文字普通识别出了测试图片的大部分单词,但是发现有一些识别不正确,我们需要用精确识别出这部分单词并代替错误的单词信息。
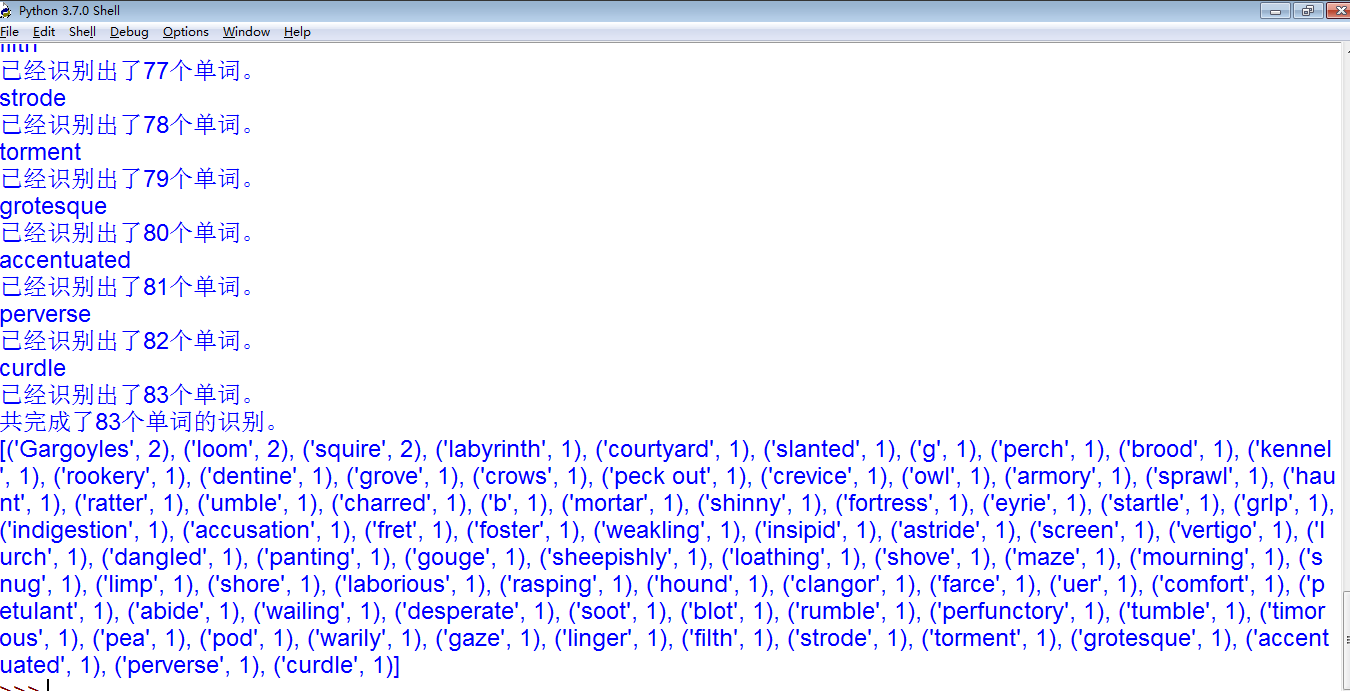
第二步得到的列表如上图,我们可以看到有些单词明显不正确,比如 (‘g’, 1), (‘b’, 1)等,我们需要找到这些单词的绝对路径,并保存在文件中,以用来精确识别。代码如下:
1 | import pickle |
运行结果如下:

可以看出我们已经找到需要删除的单词的绝对路径,然后从之前的统计列表中删除,这些绝对路径保存在listaccurate列表里面并保存在listaccurate.pkl文件中

一个要点:return只能出现在包括try, except语句的函数中,不能单独在主程序中的try, except语句。
第三步我们找到了需要精确识别的单词绝对路径并保存在文件中,下面我们就需要用精确识别找到这些单词,并更新原来的两个统计列表。
未完待续。。。。