题目:访问网址读取数据并保存在对应的文本文件里
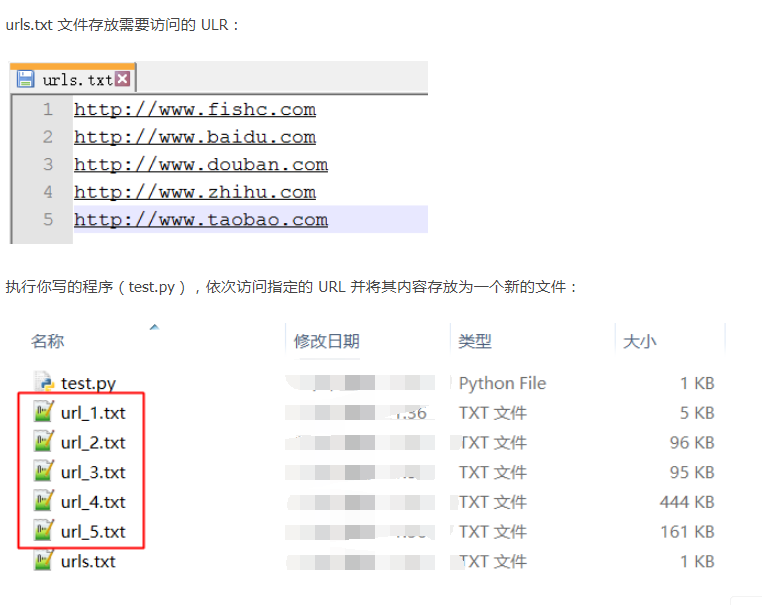
我的代码:
1 | '''此脚本通过读取urls.txt上的网站的信息,并保存在对应的文本文件里。''' |
老师的代码:
1 | '''读取网站信息并保存在对应的文件里。老师的方法与我的相似,不同之处,读取网站信息时使用了分割换行符的方法''' |
以下内容参考:Python中解码decode()与编码encode()与错误处理UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xab
使用python的时候经常会遇到文本的编码与解码问题,其中很常见的一种解码错误如题目所示,下面介绍该错误的解决方法,将‘gbk’换成‘utf-8’也适用。
(1)、首先在打开文本的时候,设置其编码格式,如:open(‘1.txt’,encoding=’gbk’);
(2)、若(1)不能解决,可能是文本中出现的一些特殊符号超出了gbk的编码范围,可以选择编码范围更广的‘gb18030’,如:open(‘1.txt’,encoding=’gb18030’);
(3)、若(2)仍不能解决,说明文中出现了连‘gb18030’也无法编码的字符,可以使用‘ignore’属性进行忽略,如:open(‘1.txt’,encoding=’gb18030’,errors=‘ignore’);
(4)、还有一种常见解决方法为open(‘1.txt’).read().decode(‘gb18030’,’ignore’
总结:
- 复习了文件的读取与写入
- decode 与 encode 的应用
- urllib 与 chardet的应用